Transcrivez et partagez vos réunions et formations grâce à Speakr !


Dans un précédent article, j’avais présenté Handy, un logiciel open source, utilisable sur à peu près n’importe quel ordinateur récent. S'il permet de transcrire facilement de la dictée ponctuelle, Handy atteint tout de même rapidement ses limites pour des utilisations plus évoluées.
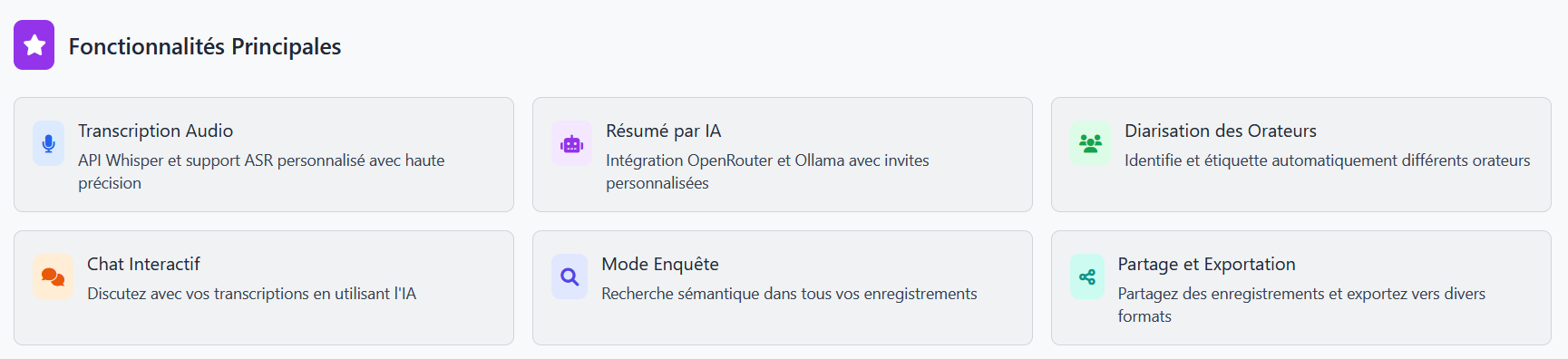
Speakr, proposé par Murtaza Nasir, et utilisable librement grâce à la licence AGPLv3, permet quant à lui d’aller beaucoup plus loin dans la transcription intelligente de l’audio en texte, puisqu’il transcrit les fichiers audios et vidéos pendant ou après leur création, y compris des fichiers de longueur importante (une formation de 96 minutes a servi de test). De plus, il reconnait les différents interlocuteurs (diarisation), agrémente les transcriptions par des notes personnelles et un résumé automatique, rend le tout partageable par liens publics ou privés, et interrogeable par l'intermédiaire d'un chat interactif, qui permet de parcourir le contenu de la transcription et de "discuter" avec celui-ci.
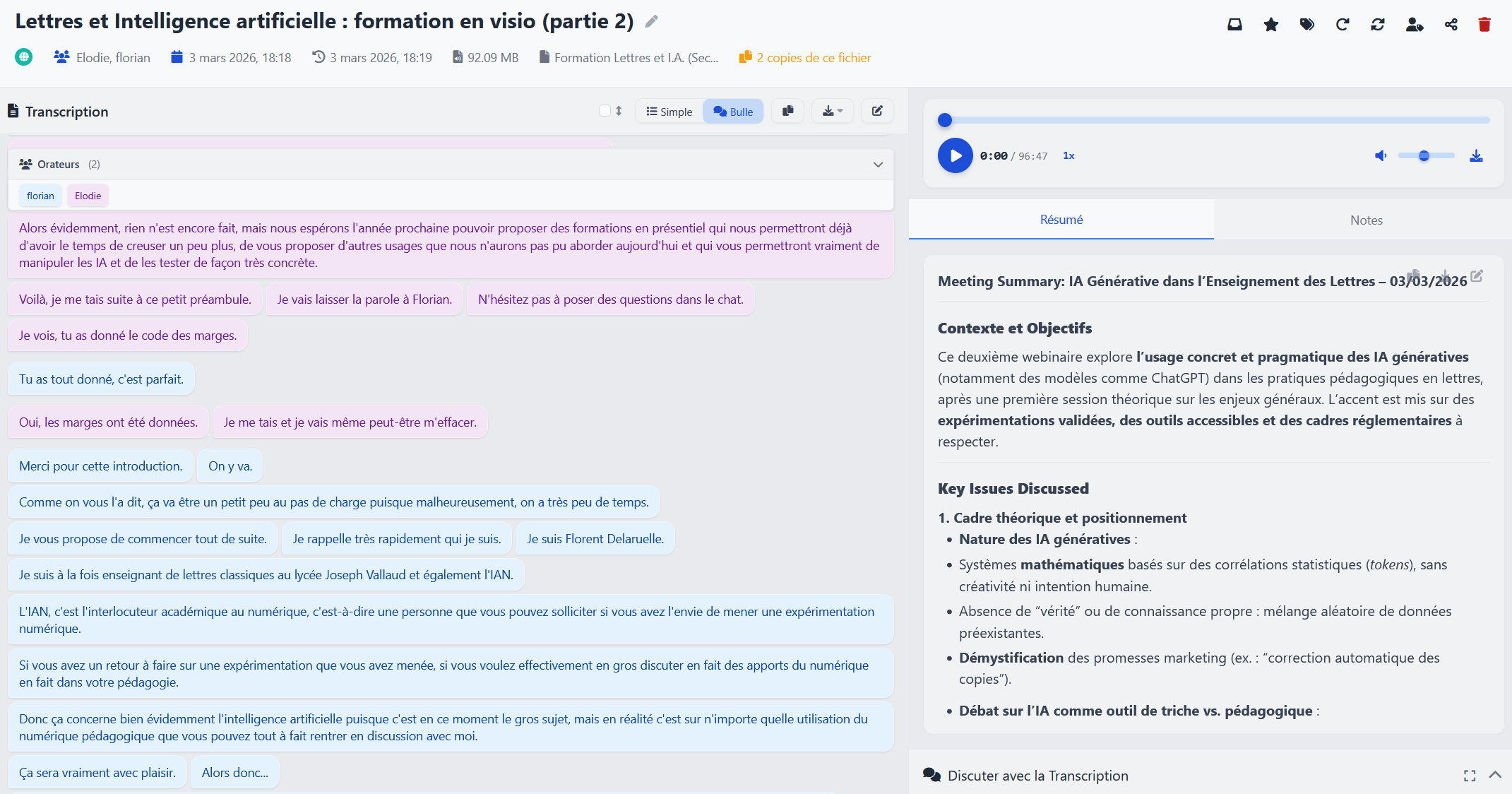
Au-delà de la simple transcription de réunions ou de formations, Speakr ouvre donc un champ des possibles assez large. On peut ainsi l'utiliser comme outil d'archivage intelligent, permettant de retrouver rapidement des informations spécifiques dans des heures d'enregistrements, ou encore comme une aide à la rédaction, en transformant des idées orales en un brouillon textuel exploitable.
Mais l'intérêt de Speakr réside également dans son potentiel pédagogique. Il devient simple de diffuser à des élèves des enregistrements de cours audios, accessibles sous forme de transcriptions textuelles et enrichis d'un résumé automatique pour faciliter la prise de notes et la révision. Le chat interactif engage quant à lui l'élève à poser des questions sur le cours, et génère des réponses contextuelles directement issues de la transcription. La diarisation permet également de distinguer les interventions du professeur de celles des élèves lors d’un échange, améliorant ainsi la compréhension et l'acquisition du cours.
Pour les formations professionnelles, Speakr peut devenir un outil utile dans l'évaluation des compétences. En analysant les transcriptions de sessions d'exercices pratiques, un formateur peut identifier les points forts et les axes d'amélioration de chaque participant, et personnaliser son accompagnement en conséquence.
Une gestion complète des utilisateurs, des prompts utilisés par le système, et du format de la sortie de la transcription embellit encore le tableau déjà très prometteur de ce logiciel disponible en version alpha (v0.8.14-alpha à l'heure de l'écriture de cet article).
Vous pouvez trouver sur le dépôt Github du projet une description plus détaillée des fonctionnalités du logiciel.
Ce logiciel utilise Docker Compose pour son déploiement, ce qui le rend totalement compatible avec la méthode décrite ici pour déployer des logiciels facilement sur un serveur.
De plus, il est tout à fait possible d'utiliser Speakr de façon totalement respectueuse du RGPD. L'utilisation et le traitement de données personnelles sont en effet possibles dans les configurations proposées dans cet article.
Voici deux façons différentes de configurer Speakr, en fonction du matériel à votre disposition. Comme souvent lorsqu'il s'agit d'intelligence artificielle, la question du matériel demeure cruciale et détermine la qualité finale de l'installation...
I. Traitement distant grâce à Albert API.
Dans la cas où vous disposez de peu de puissance de calcul, vous pouvez confier tous les traitements à Albert API, que j'ai présenté dans un précédent article.
Albert API dispose en effet, en plus des modèles classiques de génération de texte (que l'on va également utiliser), d'un modèle de transcription audio, Whisper, créé à l'origine par l'entreprise OpenAI.

Nous allons donc utiliser Albert API à la fois pour la génération du résumé automatique, pour le chat interactif permettant de "discuter" avec la transcription, mais également pour la transcription audio en tant que telle.
L'avantage de cette méthode est que votre serveur restera très peu sollicité, il ne se chargera d'aucune tâche impliquant de l'intelligence artificielle.
L'inconvénient est que le rendu est constitué de la transcription "neutre", sans reconnaissance du locuteur ni marquage temporel (diarisation et embedding). Il faut donc manipuler ensuite la transcription pour lui redonner un caractère compréhensible. Lorsqu'un seul locuteur est présent et que le passage fréquent entre l'écrit et l'audio n'est pas nécessaire, cela reste une solution satisfaisante.
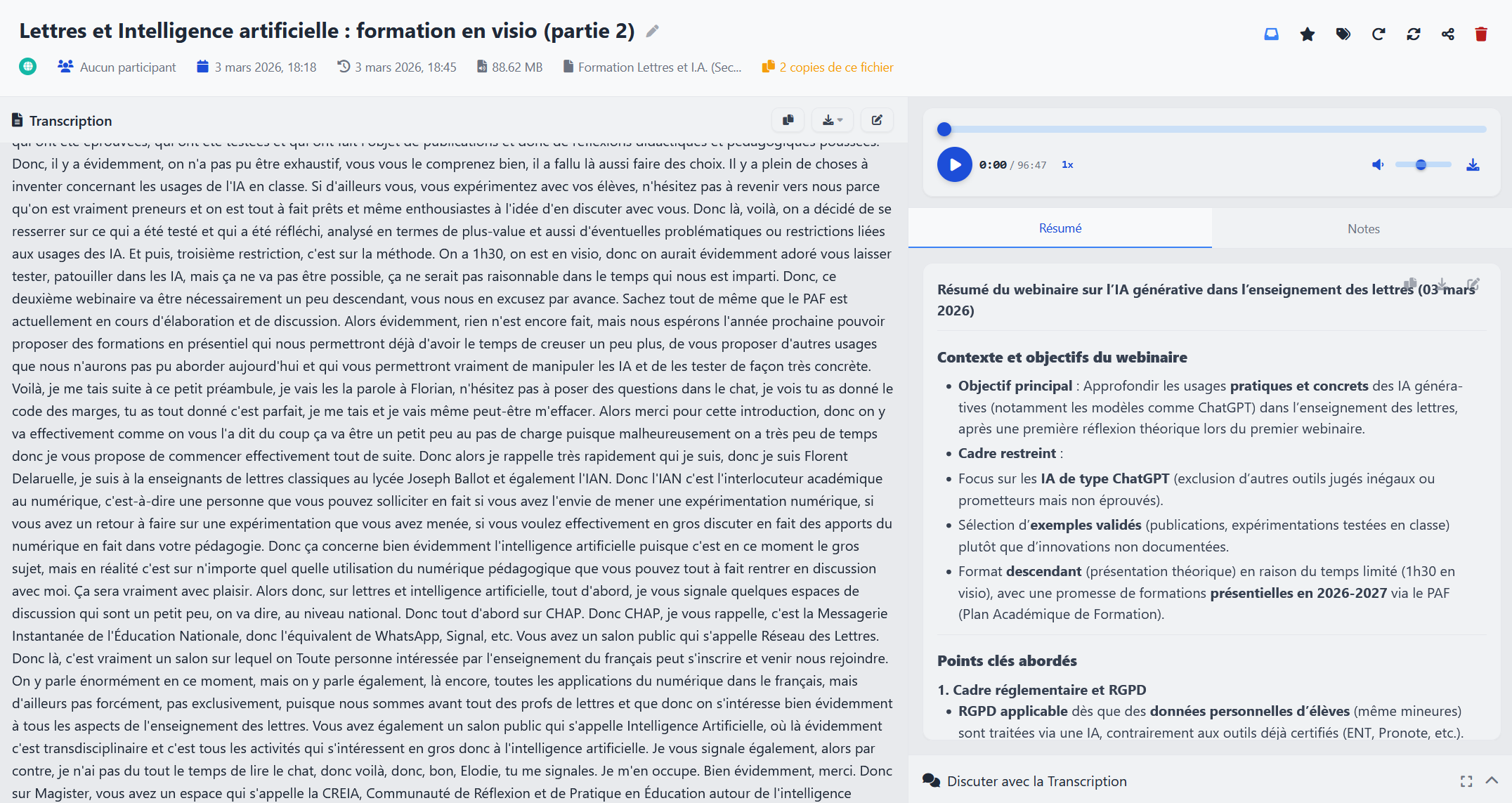
Configuration avec Albert API.
Voici la configuration à utiliser dans le fichier .env :
# Génération du résumé et du chat interactif
TEXT_MODEL_BASE_URL=https://albert.api.etalab.gouv.fr/v1
TEXT_MODEL_API_KEY=votreclefAPI
TEXT_MODEL_NAME=mistralai/Ministral-3-8B-Instruct-2512
# Génération de la transcription audio
TRANSCRIPTION_API_KEY=votreclefAPI
TRANSCRIPTION_BASE_URL=https://albert.api.etalab.gouv.fr/v1
TRANSCRIPTION_MODEL=openai/whisper-large-v3
Note : Ministral est suffisant pour le résumé et le chat interactif, mais vous pouvez utiliser un modèle plus puissant si nécessaire.

II. Traitement local grâce à WhisperX ASR.
C'est la situation idéale. Un GPU disposant d'au moins 12 Go de VRAM vous permettra d'opérer l'inférence en local grâce à WhisperX ASR, une implémentation libre de Whisper proposée par le même développeur, et donc de disposer en plus de la diarisation et de la reconnaissance complète des profils de voix.
Vous pourrez ainsi voir quel interlocuteur parle à n'importe quel moment, et un clic sur la zone concernée lancera directement la lecture du fichier audio à l'endroit précis où vous vous trouvez, rendant l'enregistrement beaucoup plus efficace et agréable à consulter.
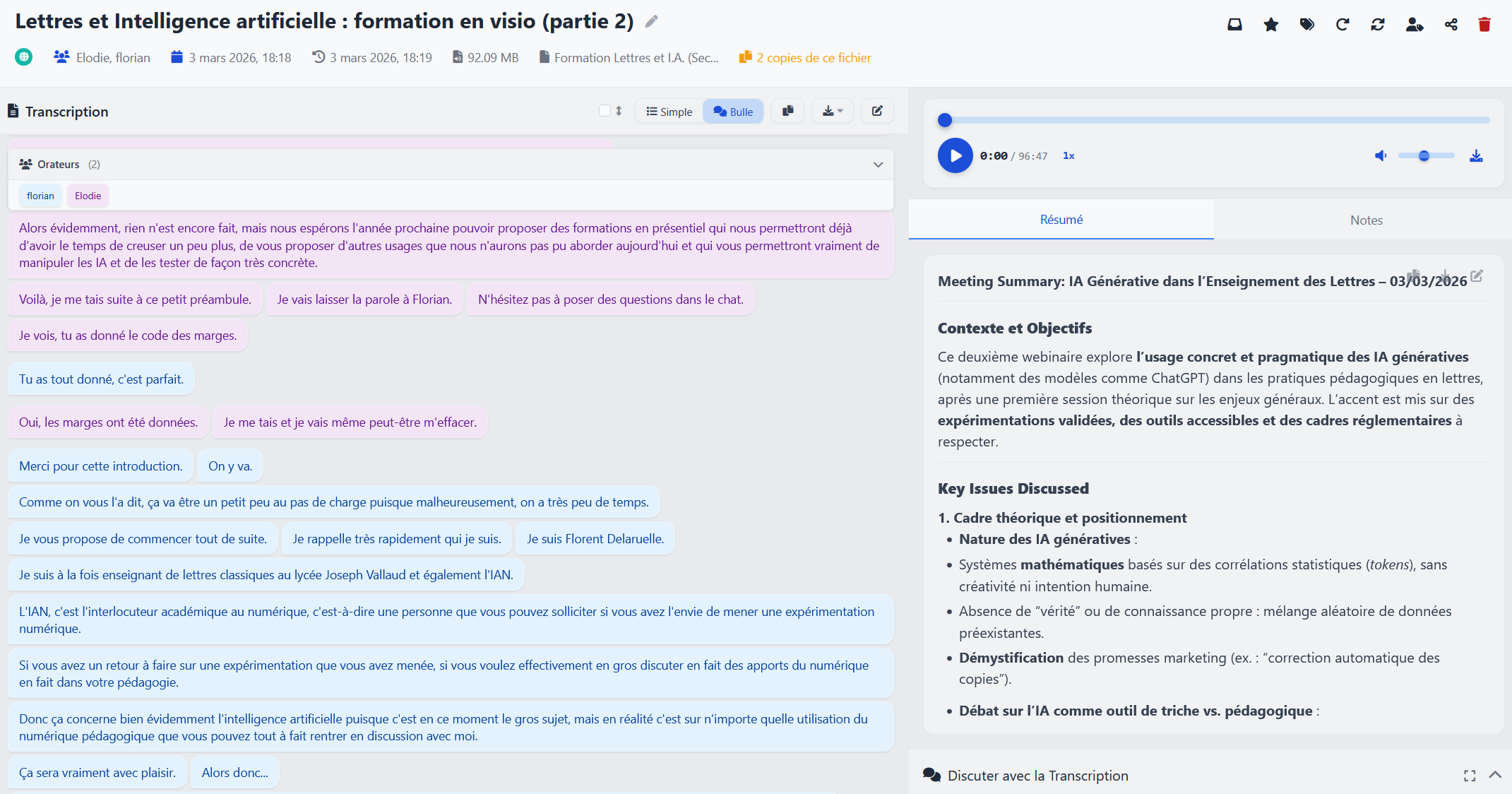
Note : Vous pouvez également utiliser une instance Ollama afin de confier la génération du résumé et le chat interactif à un modèle de votre choix.
Configuration avec WhisperX ASR.
Dans ce cas, l'installation est un peu plus longue. Il vous faudra tout d'abord configurer et lancer un conteneur Docker supplémentaire chargé de la transcription audio (configuration disponible ici). Ensuite, il est nécessaire d'adapter la configuration pour que l'inférence soit bien traitée par le conteneur WhisperX ASR. Voici une configuration fonctionnelle sur un GPU RTX-5080 de Nvidia :
# Génération du résumé et du chat interactif
TEXT_MODEL_BASE_URL=https://albert.api.etalab.gouv.fr/v1
TEXT_MODEL_API_KEY=votreclefAPI
TEXT_MODEL_NAME=mistralai/Ministral-3-8B-Instruct-2512
# Alternative : Ollama pour la génération en local du résumé et pour le chat
#TEXT_MODEL_BASE_URL=http://ollama:11434/v1
#TEXT_MODEL_NAME=ministral-3:8b # ou autre modèle local
# Base URL of your ASR service (required if USE_ASR_ENDPOINT=true)
# Supports: whisper-asr-webservice, WhisperX, and compatible services
ASR_BASE_URL=http://whisperx-asr:9000
# Enable speaker diarization (default: true)
ASR_DIARIZE=true
# Return speaker embeddings for speaker identification (WhisperX only)
# Enables automatic speaker matching across recordings
ASR_RETURN_SPEAKER_EMBEDDINGS=true
# =============================================================================
# WhisperX ASR Endpoint (with Voice Profiles)
# =============================================================================
HF_TOKEN=VotreTokenHuggingFace
DEVICE=cuda
COMPUTE_TYPE=float16
BATCH_SIZE=16
PRELOAD_MODEL=large-v3 # (ou large-v3-turbo si la puissance est insuffisante)
MAX_FILE_SIZE_MB=500
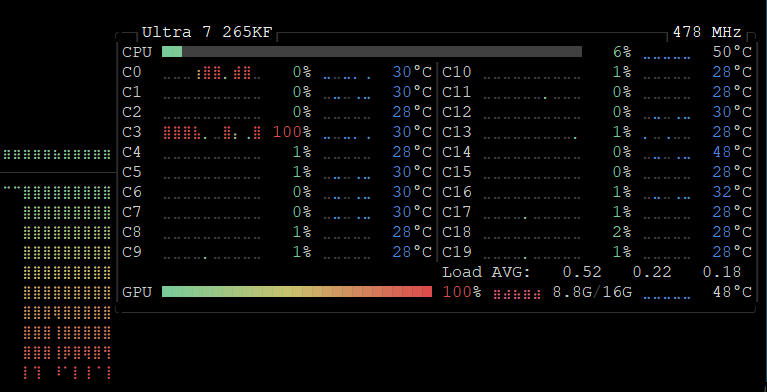
Note : L'utilisation de Whisper Large en version 3 ne consomme que 9 Go de VRAM, et sollicite de façon anecdotique le CPU, ce qui en fait une option tout à fait envisageable sur des ordinateurs de moyenne puissance. En revanche, opérer Ollama et WhisperX ASR sur la même machine en même temps nécessite une quantité importante de VRAM ou l'utilisation de modèles très légers.

Conclusion
Ce logiciel autorise une multitude de configurations et d'usages différents. Pour que l'article reste d'une taille raisonnable, j'ai choisi de traiter certains points au détriment d'autres. Si le logiciel vous intéresse, n'hésitez pas à creuser davantage les configurations possibles afin d'adapter le système à votre pratique et aux moyens dont vous disposez !